赋能 AI 全球规模化落地
助力 AI 互联的高速网络架构
高效调用全球 AI 模型
按需即开即用的专属服务器
可灵活扩展的弹性算力
公有云专线接入
三层网状网络
二层点对点连接
虚拟接入网关
提升应用程序性能
全球内容传输网络
高性能互联网接入
近终端用户托管服务
全球 AI 基础设施交付
为广告交易平台和供应方平台提供高性价比、可灵活扩展的基础设施
实现超低延时交易互联
快速扩展全球网络,支撑业务增长
构建覆盖全球的流畅音视频体验
支撑全球玩家的实时连接与稳定对战
快速扩展全球基础设施,持续提升服务性能
为 AI 应用提供就近算力与高速连接
在多云环境之间构建真正的高效互联
快速构建企业全球网络,优化跨区域用户访问体验
为跨区域 AWS 架构提供快速稳定的直连通道
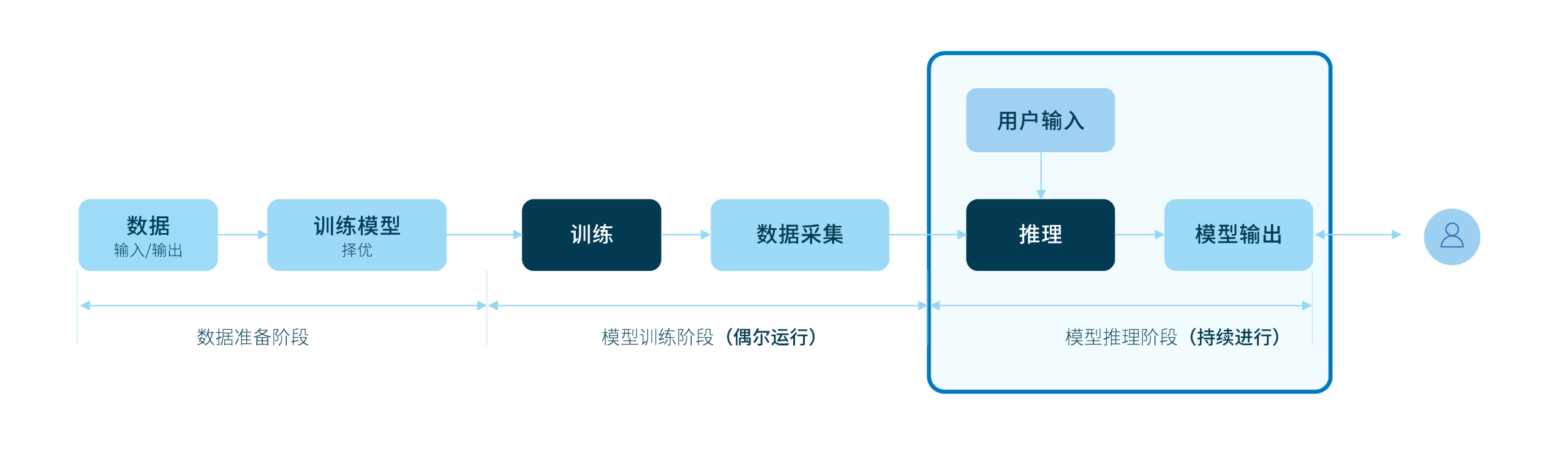
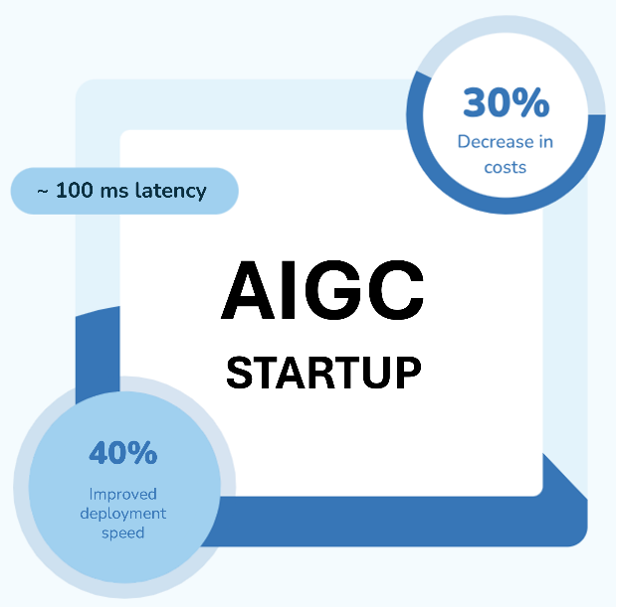
AI 与用户的每次交互都会触发推理,Agentic AI 使推理从单次响应变为多轮思考,显著增加计算复杂度。
对多数模型而言,推理可能占模型全生命周期成本的 80–90%,持续的推理导致计算需求激增,进而影响整体支出。
推理的关键,在于平衡性能、成本与用户体验。想要在全球范围内实现高可靠的规模化运行,算力必须与模型的升级、实时需求的激增精准同频。
依托 Zenlayer 优质的 GPU 基础设施,技术团队可实现模型的快速部署与高效运维,为全球用户提供稳定的智算性能。
选用顶级 GPU,经济高效地升级您的 AI 技术栈
Zenlayer 的全球专用骨干网是一张覆盖亚洲、中东、非洲、欧洲和美洲的大规模软件定义网络,专为连接全球主要 AI 枢纽而打造,并提供超低延迟路由、智能流量调度以及高带宽链路。
通过跨区域的专用连接,客户可借助安全的二层/三层(L2/L3)网络,在不同大洲之间无缝互联 GPU 集群,高效、可靠地传输训练数据、模型检查点、嵌入向量及各类数据集——完美适配多区域协同训练与全球分布式推理场景。
加速神经网络等 AI/ML 模型训练,释放智能算力潜能
充足计算吞吐量加持,让大规模计算轻松落地
无需投入昂贵硬件成本,亦可实现高质量视觉效果与沉浸式体验



















































 (2)")
